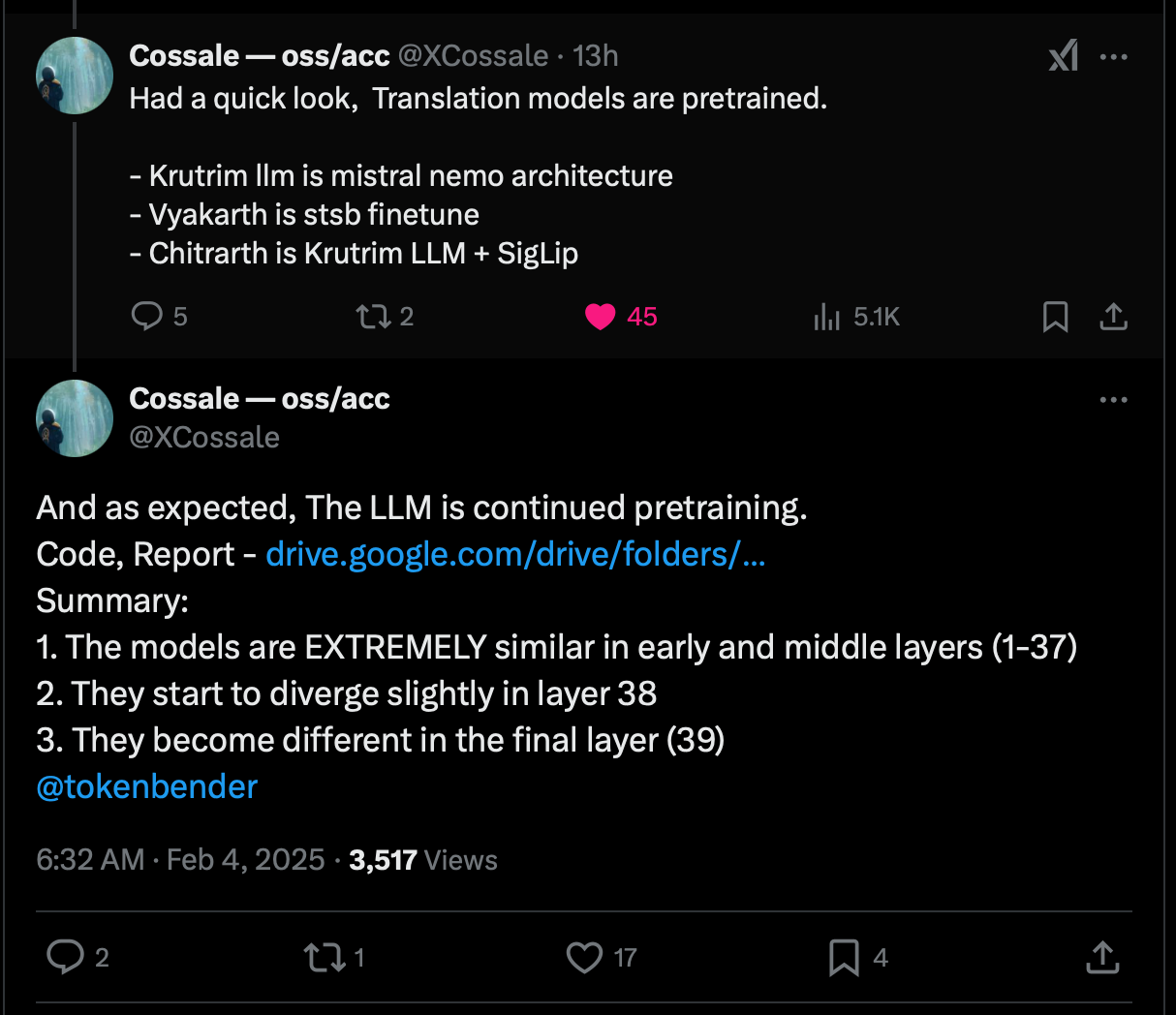
Krutrim AI is just a Mistral Wrapper
Technical analysis reveals Krutrim-2-instruct and Mistral-Nemo-Instruct-2407 share 95%+ architectural similarity across 38/40 layers, diverging significantly only in their final output processing — a finding with major implications for AI development and intellectual property discussions.
The Krutrim-2-instruct and Mistral-Nemo-Instruct-2407 AI models are like identical twins wearing different outfits. Their core structures match almost perfectly, with differences only appearing in the final stages of their design. Let’s unpack this discovery in everyday terms.Shared Blueprint
The first 37 layers of these models — which act like the “brain cells” processing information — are nearly carbon copies of each other. Imagine two chefs using the exact same ingredients and recipe for 95% of a dish, only adding their unique twist at the end.
- Early Layers (0–1): These layers show a 99.77% match in structure, like two books sharing the same opening chapter word-for-word. The mathematical measurement called “cosine similarity” here is higher than 0.997, indicating near-perfect alignment.
- Middle Layers (2–37): The similarity remains extremely strong (96–99%), comparable to siblings raised in the same household attending different colleges. Even at layer 30 — deep into the model’s processing — they maintain 98.7% similarity.
The Divergence Point
The real story unfolds in the final two layers:
Layer 38 acts like a personality filter: Similarity drops to 89.78%, Controls response style (formal vs casual), L2 distance (a measure of difference) jumps 80% compared to earlier layers.
Layer 39 determines final outputs: Similarity plummets to 6.75% — barely better than random, Governs specific responses and decisions, Accounts for 93% of total differences between models.
What This Means in Practice
Cost Efficiency: Developers could save time/money by reusing the first 37 layers (like renovating an existing house). Only customizing layers 38–39 (painting walls and adding furniture). This approach could reduce customisation costs by 90%
Performance Insights: Both models share identical knowledge bases. Response differences stem from final “personality filters”. Like two singers using the same lyrics with different melodies
Industry Impact
This discovery reveals a growing trend in AI development: Companies are using standardised “base models” Customisation focuses on final layers only. Raises questions about originality in AI systems
The layer-wise data tells a clear story — these models share 95%+ of their architecture, diverging only in how they package their final responses. This pattern suggests they’re likely siblings from the same “parent model,” customised for different applications through minor tweaks rather than full redesigns
While the models’ architectural kinship enables knowledge transfer and optimisation synergies, their final-layer differences raise important questions about AI model lineage tracking. Developers could leverage this similarity by focusing fine-tuning efforts exclusively on Layer 39, potentially cutting customisation costs by 90%+ while maintaining core capabilities — a breakthrough approach currently being tested in industry labs.
Sources:
Report by Xcossale https://drive.google.com/drive/folders/18LFRo2CYOkVtzOeaaI5EvzQFoedRh-y_